#22 Bug Bounty. Wayback Machine crawl data.
Здравствуйте, дорогие друзья.
Мы можем выполнять активное сканирование самостоятельно, но можно и проще использовать третьи лица для этого или вендоров. Wayback Machine — это архив всего интернета.
По сути, с помощью Wayback Machine можно заходить на каждый веб-сайт и сканировать его, делая скриншоты и запись в базу данных.
● https://web.archive.org/
Затем эти конечные точки могут быть запрошены, чтобы получить каждый путь, который когда-либо был на сайте. Результаты сканирования можно увидеть на скриншоте:
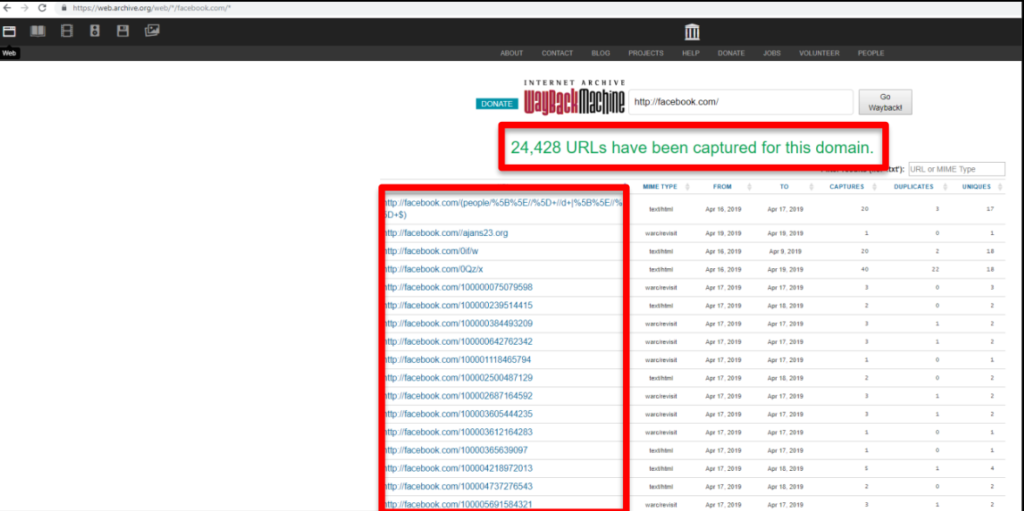
Перейдя на «https://web.archive.org/web/*/facebook.com/*», Вы увидите список путей, которые просканировала машина Wayback. Затем мы можем использовать фильтр для поиска определенных файлов. Например, такие как все, что заканчивается на «.bak», поскольку они могут содержать полезную резервную информацию.
Среди других интересных фильтров есть:
● .zip
● .config
● /admin/
● /api/
Вы можете использовать эти данные не только для поиска интересных файлов, но и для поиска уязвимости, просматривая данные. Например, если Вы видите путь «example.com/?redirect=something.com», то Вы можете проверить open redirects и SSRF-уязвимости.
Если Вы видите параметр GET «msg=», вы можете проверить XSS. Список можно продолжать днями. Некоторым людям нравится использовать веб-интерфейс для получения списка путей, но я предпочитаю использовать командную строку.
Я создал небольшой скрипт, который можно использовать для получения списка путей из машины Wayback:
● https://github.com/ghostlulzhacks/waybackMachine
Прежде чем Вы решите самостоятельно сканировать веб-сайт, проверьте с помощью Wayback Machine. Это может сэкономить Вам много времени и усилий, используя данные, просканированные другими людьми. Один раз вы получаете данные, начинаете искать интересные файлы и параметры GET, которые могут быть уязвимыми.
Общие данные сканирования
Как и The Wayback Machine, Common Crawl также регулярно сканирует Интернет на предмет конечных точек. Кроме того, как и в случае с Wayback Machine, эти данные общедоступны, и мы можем использовать их для пассивного получения списка конечных точек на сайте.
● http://commoncrawl.org/
Следующий сценарий можно использовать для запроса данных, предоставленных общим сканированием:
● https://github.com/ghostlulzhacks/commoncrawl
Выполните следующую команду, чтобы запустить скрипт:
python cc.py -d <Домен>
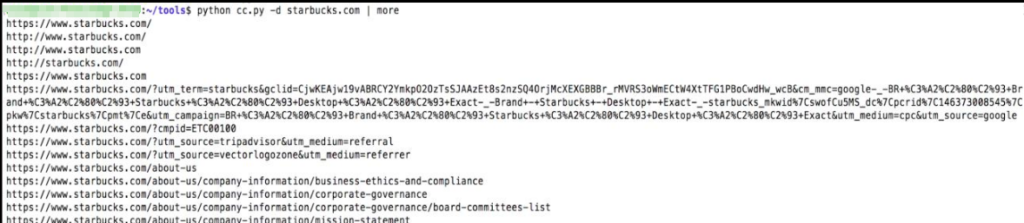
Это создаст огромный список конечных точек, начиная с 2014 года. Вы определенно захотите передать вывод в файл, чтобы иметь возможность проанализировать его позже. Обратите внимание, что, поскольку, некоторые URL-адреса относятся к 2014 году, они могут больше не существовать, поэтому большая часть этих URL-адресов не работает.
Брутфорс каталогов
Сканирование веб-сайта — хороший способ найти конечные точки, которые нужны администратору. Но как насчет этих скрытых активов? Вот где перебор каталогов подходит как нельзя лучше. В зависимости от Ваших списков слов, Вы можете найти все виды интересных конечных точек, такие как файлы резервных копий, дампы ядра, файлы конфигурации и многое другое.
Существует множество инструментов для подбора каталогов, но я обычно использую инструмент gobuster. Вы должны быть знакомы с этим инструментом по перечислению субдоменов.
● https://github.com/OJ/gobuster
Обратите внимание, что результаты, которые Вы получите, полностью зависят от используемого Вами списка слов. Перейдите назад в главу о списках слов, если Вам нужен один из самых популярных списков слов, используемых профессионалами. Выполните следующую команду, чтобы запустить Gobbuster:
./gobuster dir -k -w <Wordlist> -u <URL>
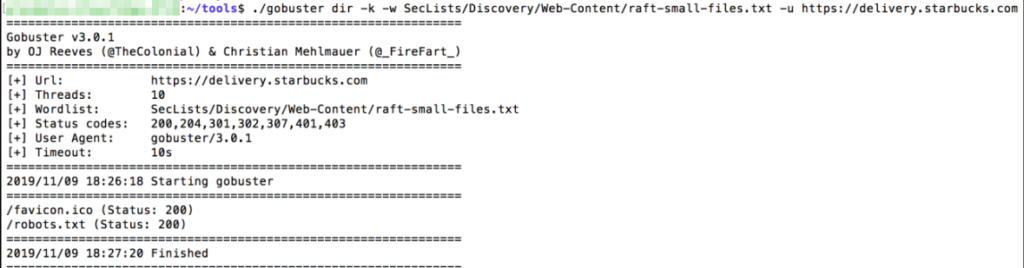
Самое главное, что нужно помнить, это то, что если Вы хотите получить хорошие результаты, используйте хороший список слов.
Вывод
Обнаружение контента может выполняться пассивно или активно. Wayback Machine, и Common Crawl можно использовать для поиска конечных точек Вашей цели.
Эти ресурсы хороши тем, что они полностью пассивны. Вы также можете самостоятельно активно сканировать целевую конечную точку, чтобы собирать данные в режиме реального времени.
Сканирование полезно для поиска общедоступных конечных точек, но как насчет скрытых или неправильно настроенных конечных точек?
Брут-форс каталогов идеально подходит для поиска скрытых конечных точек. Просто убедитесь, что Вы используете высококачественный список слов. Когда дело доходит до брут-форса Вашего списка слов — это может помочь Вам в поиске.
На этом все. Всем хорошего дня!
#1 Bug Bounty. Подготовка к Bug Bounty. Введение.
#2 Bug Bounty. Организация. Введение.
#3 Bug Bounty. Заметки. Введение.
#4 Bug Bounty. Подготовка к охоте. База знаний.
#6 Bug Bounty 101. Выбор платформы.
#7 Bug Bounty. Выбор правильной цели.
#8 Bug Bounty. Методология — рабочие процессы.
#9 Bug Bounty. Рабочий процесс GitHub.
#10 Bug Bounty. Гугл Дорки Рабочий процесс.
#11 Bug Bounty. Эксплойты — Рабочий процесс.
#12 Bug Bounty. CMS — Рабочий процесс.
#13 Bug Bounty. Брутфорс — Рабочий процесс.
#14 Bug Bounty. Раздел 2. Разведка.
#15 Bug Bounty. Reverse Whois.
#17 Bug Bounty. Разведка — Фаза 2. Словарь.
#18 Bug Bounty. Перечисление поддоменов.
#19 Bug Bounty. Поисковый движок.