#21 Bug Bounty. Разрешения DNS.
В процессе перечисления поддоменов, Вы должны были сгенерировать из них большой список. Чтобы начать исследовать эти конечные точки, Вам нужно знать какие из их активные.
Для этого мы можем выполнить поиск DNS по домену. чтобы увидеть, содержит ли он запись A. Если это так, мы знаем, что поддомен активен.
Большинство инструментов перечисления поддоменов делают это автоматически, но некоторые инструменты этого не делают. Если у Вас есть список поддоменов, Вы можете использовать Massdns для того, чтобы определить, какие из доменов являются активными.
● https://github.com/blechschmidt/massdns
Инструмент написан на C и требует, чтобы мы его построили, прежде чем мы сможем его использовать. Для этого выполните следующую команду:
git install https://github.com/blechschmidt/massdns.git
cd massdns
make
Обратите внимание, что для анализа действующих доменов нам потребуется проанализировать вывод инструмента. Это можно сделать с помощью формата json, и я буду использовать для этого JQ.
JQ — это парсер json из командной строки.
● https://github.com/stedolan/jq
Еще одна вещь, которую следует отметить, это то, что у вас также должен быть список преобразователей DNS для инструментов использования. Самый популярный из них — Googles «8.8.8.8». Если у Вас большой список, то Вы можете добавить больше. Инструмент можно запустить с помощью следующей команды:
./bin/massdns -r resolvers.txt -t A -o J subdomains.txt | jq
‘select(.resp_type==»A») | .query_name’ | sort -u
Resolvers.txt должен содержать Ваш список распознавателей DNS, а subdomains.txt содержит домены, которые Вы хотите проверить.
Затем это передается в JQ, где мы анализируем все домены, которые разрешаются в IP. Затем мы используем команду сортировки, чтобы удалить все дубликаты.
Скриншот
Когда Вы имеете дело с тысячами целей, пролистывать их намного проще, с помощью скринов, нежели заходить на каждый сайт вручную.
Просто взглянув на снимок экрана, Вы можете определить несколько вещей, таких как его технология, старая ли она, интересно ли это выглядит, есть ли функция входа в систему и многое другое.
Было несколько случаев, когда просмотр снимков экрана приводил меня прямо к удаленному выполнение кода (RCE). При сборе скриншотов я обычно использую инструмент eyewitness:
● https://github.com/FortyNorthSecurity/EyeWitness
После того, как вы загрузите и установите инструмент, вы можете запустить его со следующим команда:
Python3 EyeWitness.py -f subdomains.txt —web
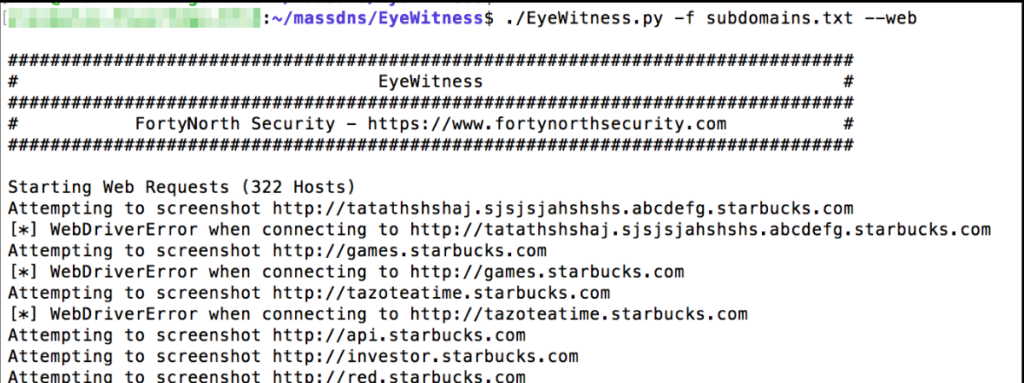
EyeWitness попытается сделать скриншот каждого домена в списке, который был передан к нему. После завершения работы инструмента Вы можете прокручивать каждый из экранов, чтобы найти интересные конечные точки.
Обнаружение контента
Введение
Обнаружение контента — жизненно важный процесс на этапе разведки. Неспособность правильного выполнения этого этапа приведет к большому количеству пропущенных уязвимостей. Главный целью обнаружения контента является поиск конечных точек в целевом домене. Вы ищете такие вещи, как файлы журналов, файлы конфигурации, интересные технологии или приложения, а также все остальное, что размещено на веб-сайте.
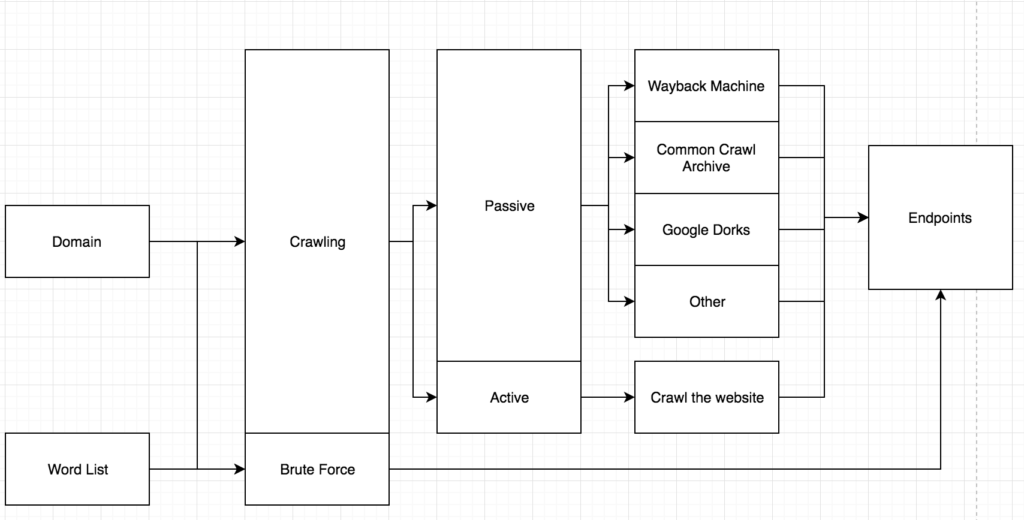
Самостоятельное сканирование
Один из лучших способов найти конечные точки на цели — обход приложения. Сканирование веб-сайта включает в себя рекурсивное посещение каждой ссылки и сохранение каждой ссылки на веб-страницу рекурсивно. Это отличный способ найти конечные точки, но Вы, вероятно, не найдете никаких скрытых конечных точек таким образом.
Инструменты, которые я использовал в прошлом, перестали работать правильно, поэтому я создал собственный инструмент для выполнения сканирования. Обычно я стараюсь использовать общедоступные инструменты, но иногда Вам нужно будет создавать свой.
● https://github.com/ghostlulzhacks/crawler/tree/master
Обратите внимание, что сканирование большого сайта может оказаться невозможным, так как в нем могут быть миллионы ссылок внутри приложения. По этой причине, я вообще глубже 2-го уровня не погружаюсь. Для обхода сайта можно использовать следующую команду.
python3 crawler.py -d <URL> -l <Levels Deep to Crawl>
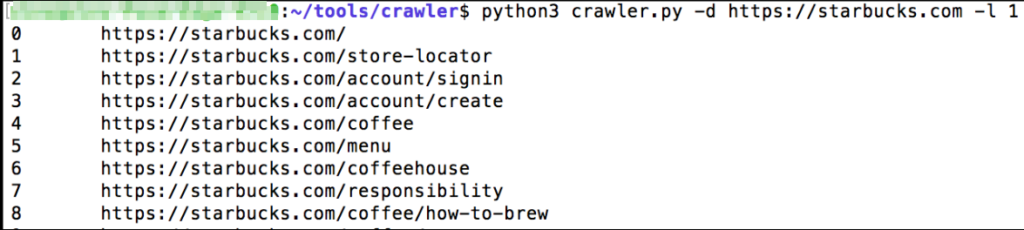
Если Вы найдете альтернативный инструмент для использования, не стесняйтесь использовать его. Основная идея здесь состоит в том, чтобы получить список URL-адресов на сайте. Затем эти URL-адреса можно проверить, чтобы найти интересные конечные точки, технологии отпечатков пальцев и поиск уязвимостей.
На этом все. Всем хорошего дня!
#1 Bug Bounty. Подготовка к Bug Bounty. Введение.
#2 Bug Bounty. Организация. Введение.
#3 Bug Bounty. Заметки. Введение.
#4 Bug Bounty. Подготовка к охоте. База знаний.
#6 Bug Bounty 101. Выбор платформы.
#7 Bug Bounty. Выбор правильной цели.
#8 Bug Bounty. Методология — рабочие процессы.
#9 Bug Bounty. Рабочий процесс GitHub.
#10 Bug Bounty. Гугл Дорки Рабочий процесс.
#11 Bug Bounty. Эксплойты — Рабочий процесс.
#12 Bug Bounty. CMS — Рабочий процесс.
#13 Bug Bounty. Брутфорс — Рабочий процесс.
#14 Bug Bounty. Раздел 2. Разведка.
#15 Bug Bounty. Reverse Whois.
#17 Bug Bounty. Разведка — Фаза 2. Словарь.
#18 Bug Bounty. Перечисление поддоменов.