#15 Gray Hat C#. Руководство для хакера по созданию и автоматизации инструментов безопасности. Использование логических слепых SQL-уязвимостей. Как работают слепые SQL-инъекции?
Здравствуйте, дорогие друзья.
Слепая SQL-инъекция, также известная как слепая SQL-инъекция на основе логических значений, — это процедура, при которой злоумышленник не получает прямую информацию из базы данных, но может извлекать информацию из БД косвенно, обычно по 1 байту за раз, запрашивая true-или-false вопросы.
Как работают слепые SQL-инъекции
Слепые SQL-инъекции требуют немного больше кода, чем эксплойты UNION, чтобы эффективно использовать уязвимость SQL-инъекций, и для их выполнения требуется гораздо больше времени, поскольку необходимо очень много HTTP-запросов. Они также гораздо более шумны на стороне сервера, чем эксплойт UNION, и могут оставить больше свидетельств в журналах.
При выполнении слепой инъекции SQL, Вы не получаете прямой обратной связи от веб-приложения; вместо этого Вы полагаетесь на метаданные, такие как изменения поведения, чтобы получить информацию из базы данных. Например, используя ключевое слово MySQL RLIKE для сопоставления значений в базе данных с регулярным выражением, как показано в листинге ниже, мы можем вызвать отображение ошибки в BadStore.
|
1 |
searchquery=fdsa'+RLIKE+0x28+AND+' |
При передаче в BadStore, RLIKE попытается проанализировать строку в шестнадцатеричной кодировке, как регулярное выражение, что приведет к ошибке (см. листинг ниже), поскольку переданная строка является специальным символом в регулярных выражениях. Символ открывающей скобки [ ( ] (0x28 в шестнадцатеричном формате) обозначает начало группы выражений, которую мы также использовали для сопоставления имен пользователей и хэшей паролей в эксплоите UNION. Символ открывающей скобки должен иметь соответствующую закрывающую скобку [ ) ]; в противном случае синтаксис регулярного выражения будет недействительным.
|
1 |
Got error 'parentheses not balanced' from regexp |
Круглые скобки не сбалансированы, поскольку закрывающая скобка отсутствует. Теперь мы знаем, что можем надежно контролировать поведение BadStore, используя истинные и ложные SQL-запросы, вызывающие ошибки.
Использование RLIKE для создания истинных и ложных ответов
Мы можем использовать оператор CASE в MySQL (который ведет себя как оператор Case в C-подобных языках) для детерминированного выбора хорошего или плохого регулярного выражения, для анализа RLIKE. Например, листинг ниже возвращает истинный ответ.
|
1 |
searchquery=fdsa'+RLIKE+(SELECT+(CASE+WHEN+(1=1 [1] )+THEN+0x28+ELSE+0x41+END))+AND+' |
Оператор CASE сначала определяет, является ли 1=1 [1] истинным. Поскольку это уравнение истинно, 0x28 возвращается как регулярное выражение, которое RLIKE попытается проанализировать, но поскольку (не является допустимым регулярным выражением, веб-приложение должно выдать ошибку. Если мы манипулируем критерием CASE 1 = 1 (который оценивается как true) как 1 = 2, веб-приложение больше не выдает ошибку. Поскольку 1 = 2 оценивается как false, 0x41 (заглавная буква A в шестнадцатеричном формате) возвращается для анализа RLIKE и не вызывает ошибку синтаксического анализа.
Задавая веб-приложению вопросы типа «верно или ложно» (равнозначно ли это??), мы можем определить, как оно ведет себя, а затем, основываясь на этом поведении, определить, был ли ответ на наш вопрос истинным или ложным.
Использование ключевого слова RLIKE для соответствия критериям поиска
Полезная нагрузка параметра searchquery в листинге ниже, должна возвращать истинный ответ (ошибку), поскольку длина количества строк в таблице userdb больше 1.
|
1 |
searchquery=fdsa'+RLIKE+(SELECT+(CASE+WHEN+((SELECT+LENGTH(IFNULL(CAST(COUNT() +AS+CHAR),0x20))+FROM+userdb)=1 [1] )+THEN+0x41+ELSE+0x28+END))+AND+' |
Используя операторы RLIKE и CASE, мы проверяем, равна ли длина счетчика пользовательской базы данных BadStore 1. Оператор COUNT() возвращает целое число, которое представляет собой количество строк в таблице. Мы можем использовать это число, чтобы значительно сократить количество запросов, необходимых для завершения атаки.
Если мы изменим полезную нагрузку, чтобы определить, равна ли длина количества строк 2 вместо 1 [1], сервер должен вернуть истинный ответ, содержащий ошибку «скобки не сбалансированы». Например, предположим, что BadStore имеет 999 пользователей в таблице userdb. Хотя вы могли бы ожидать, что нам потребуется отправить не менее 1000 запросов, чтобы определить, было ли число, возвращаемое функцией COUNT(*), больше 999, мы можем перебрать каждую отдельную цифру (каждый экземпляр 9) гораздо быстрее, чем могли бы перебрать целое число (999). Длина числа 999 равна трем, поскольку 999 состоит из трех символов. Если вместо перебора всего числа 999, мы подберем первую, вторую, а затем третью цифры по отдельности, мы получим все число 999 всего за 30 запросов — до 10 запросов на одно число.
Определение и печать количества строк в таблице userdb
Чтобы сделать это немного более понятным, давайте напишем метод Main(), чтобы определить, сколько строк содержится в таблице userdb. С помощью цикла for, показанного в листинге ниже, мы определяем длину количества строк, содержащихся в таблице userdb.

Мы начинаем с нуля, а затем увеличиваем countLength на 1 каждый раз в цикле, проверяя, содержит ли ответ на запрос истинную строку «скобки не сбалансированы». Если да, то мы выходим из цикла for с правильным значением countLength, которое должно быть равно 23.
Затем мы запрашиваем у сервера количество строк, содержащихся в таблице userdb, как показано в листинге ниже.

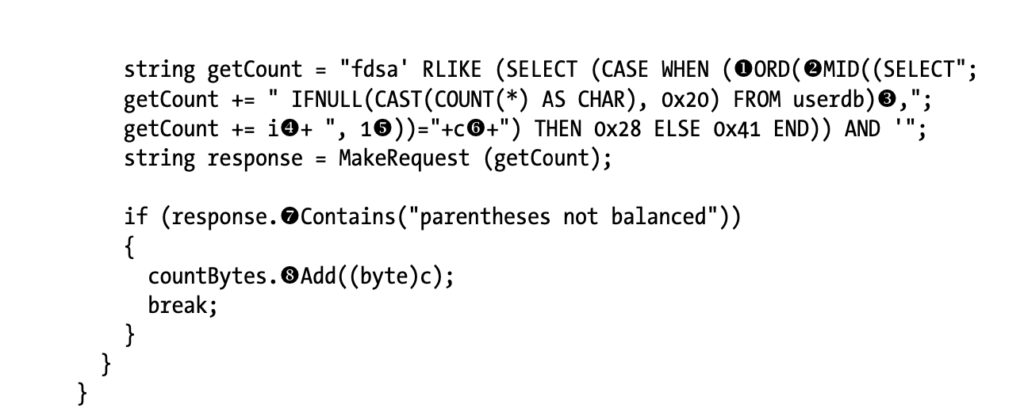
Полезная нагрузка SQL, используемая в листинге ниже, немного отличается от предыдущих данных SQL, используемых для получения счетчика. Мы используем функции ORD() [1] и MID() [2] SQL. Функция ORD() преобразует заданные входные данные в целое число, а функция MID() возвращает определенную подстроку на основе начального индекса и возвращаемой длины. Используя обе функции, мы можем выбрать по одному символу из строки, возвращаемой оператором SELECT, и преобразовать его в целое число. Это позволяет нам сравнивать целочисленное представление байта в строке со значением символа, которое мы проверяем в текущем взаимодействии.
Функция MID() принимает три аргумента: строку, из которой вы выбираете подстроку [3]; начальный индекс (который отсчитывается от 1, а не от 0, как можно было бы ожидать) [4]; и длину подстроки для выбора [5]. Обратите внимание, что второй аргумент [4] MID() определяется текущей итерацией самого внешнего цикла for, где мы увеличиваем i до длины счетчика, определенной в предыдущем цикле for. Этот аргумент выбирает следующий символ в строке для проверки, по мере ее итерации и увеличения. Внутренний цикл for перебирает целочисленные эквиваленты символов ASCII от 0 до 9. Поскольку мы пытаемся получить только количество строк в базе данных, нас интересуют только числовые символы.
Обе переменные i [4] и c [6] используются в полезных данных SQL во время атаки с логическим внедрением. Переменная i используется в качестве второго аргумента в функции MID(), определяя позицию символа в значении базы данных, которое мы будем тестировать. Переменная c — это целое число, с которым мы сравниваем результат ORD(), которое преобразует символ, возвращаемый MID(), в целое число. Это позволяет нам перебирать каждый символ в заданном значении в базе данных и перебирать символ, используя вопросы типа «верно-неверно».
Когда полезная нагрузка возвращает ошибку «скобки не сбалансированы» [7], мы знаем, что символ с индексом i равен целому числу c внутреннего цикла. Затем мы приводим c к байту и добавляем его в экземпляр List [8], созданный перед циклом. Наконец, мы выходим из внутреннего цикла и перебираем внешний цикл, а после завершения циклов for преобразуем List в печатаемую строку.
Затем эта строка выводится на экран, как показано в листинге ниже.
|
1 |
int count = int.Parse(Encoding.ASCII. [1] GetString(countBytes.ToArray())); Console.WriteLine("There are "+count+" rows in the userdb table"); |
Мы используем метод GetString() [1] (из класса Encoding.ASCII) для преобразования массива байтов, возвращаемого функцией countBytes.ToArray(), в удобочитаемую строку. Затем эта строка передается в функцию int.Parse(), которая анализирует ее и возвращает целое число (если строку можно преобразовать в целое число). Затем строка печатается с помощью Console.WriteLine().
На этом все. Всем хорошего дня!