#2 Python для пентестера. Email-парсер на Python 3. Часть 2.
Здравствуйте, дорогие друзья.
Мы продолжаем писать наш email-парсер.
В предыдущей части мы создали необходимые нам переменные, одна из которых будет хранить url-адреса, а другая, хранит электронные адреса.
Вспомним, что мы запрограммировали проверку 100 url-адресов, которые она находит.
Теперь же, мы хотим сообщить программе, все электронные ящики, находящиеся в этих 100 url-адресах. Первое, что нам нужно сделать, так это сформировать url. Предлагаю создать переменную, под названием «parts», равная «urlib.parse», а затем url отделится от url, который у нас есть. Имейте ввиду, что это сканируемый url-адрес, и он будет переключаться каждый раз:
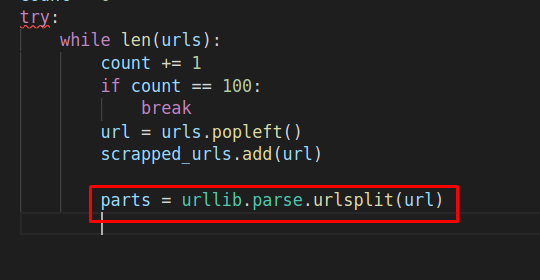
Далее, нам нужно определить базовый url-адрес. Для этого объявляем переменную «base_url», и прописываем следующий код: «base_url = ‘{0.scheme}://{0:netloc}’.format(parts)»:
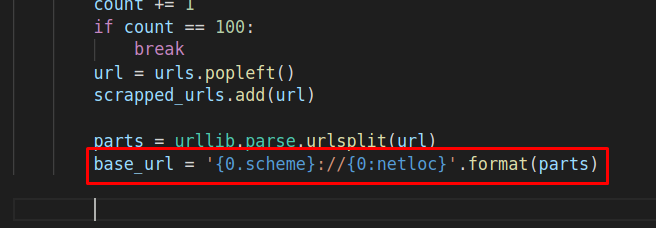
Нужно указать путь, при помощи path, в которой содержится список, где завершением будет оператор «if» — если – открываем одинарные кавычки, и прописываем в них прямой слеш, и далее указываем путь, иначе указываем url-адрес: «path = url[:url.rfind(‘/’)+1] if ‘/’ in parts.path else url»:
![path = url[:url.rfind(‘/’)+1] if ‘/’ in parts.path else url](https://timcore.ru/wp-content/uploads/2022/01/screenshot_3.png)
Мы можем вывести эту информацию, с помощью «print». Дело в том, что мы обрабатываем указанный url-адрес, и конструкция примет вид: «print(‘[%d] Processing %s ‘ % (count, url))». Будет простой вывод на экран, какой url мы в данный момент сканируем, и какой номер этого адреса от 1 до 100:
![print(‘[%d] Processing %s ‘ % (count, url))](https://timcore.ru/wp-content/uploads/2022/01/screenshot_4.png)
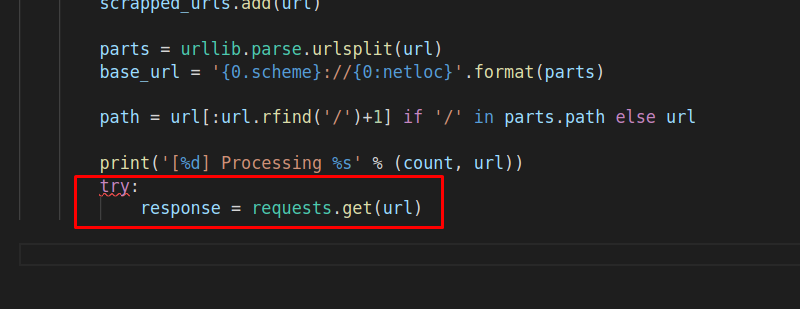
Сразу после этого, мы будем пытаться подключиться к url-адресу, поэтому мы просто попытаемся отправить запросы на конкретный url-адрес, и сохраним его в ответе, потому что в нем будут содержаться все электронные ящики, которые мы спарсили.
Получится следующая конструкция: «try: response = requests.get(url)»:
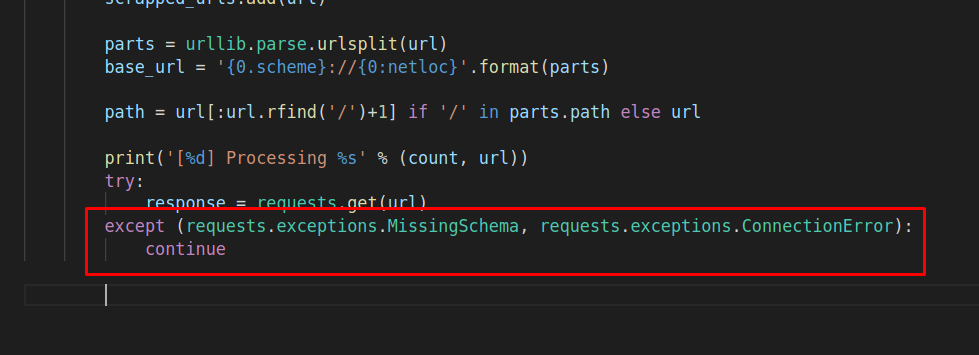
В случае, если это не сработает, мы будем выводить некоторые ошибки следующего вида:
«except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError): continue», и мне не хотелось бы останавливать программу, из-за ошибки подключения к одному из url-адресов:
Создадим новую переменную «new_emails», чтобы она была равна множеству «set()», в котором будут содержаться «re.findall()», находящие все строки с заданным шаблоном, между скобками, так что я просто введу следующие выражения (можно просто скопировать их): new_emails = set(re.findall(r»[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+», response.text, re.I))
![new_emails = set(re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", response.text, re.I))](https://timcore.ru/wp-content/uploads/2022/01/screenshot_7-1024x376.png)
Теперь мы можем обновить электронные ящики, с помощью следующей строки кода:
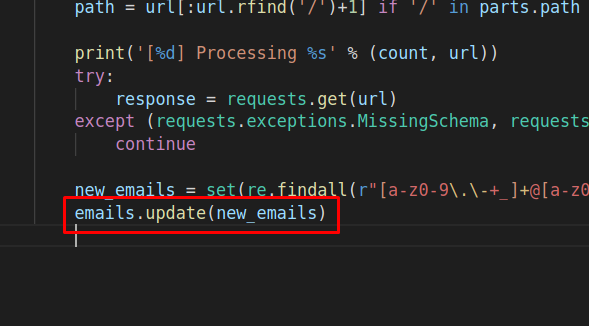
Итак, на данный момент, нам удалось создать шаблон электронных ящиков.
В следующей статье, мы перейдем к завершающей стадии написания кода парсера, чтобы в конце сканирования всех ссылок, мы могли бы иметь возможность выводить их на экран.